- [1] J. L. Schönberger and J.-M. Frahm, “Structure-from-Motion Revisited,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2016.
- [2] J. L. Schönberger, E. Zheng, M. Pollefeys, and J.-M. Frahm, “Pixelwise View Selection for Unstructured Multi-View Stereo,” in European Conference on Computer Vision (ECCV). Cham: Springer, 2016.
- [3] J. Wang, M. Chen, N. Karaev, A. Vedaldi, C. Rupprecht, and D. Novotny, “VGGT: Visual Geometry Grounded Transformer.”
- [4] Y. Wang et al., “π3: Permutation-Equivariant Visual Geometry Learning,” Sep. 09, 2025, arXiv: arXiv:2507.13347.
- [5] B. Huang et al., “2D Gaussian Splatting for Geometrically Accurate Radiance Fields,” in ACM SIGGRAPH 2024 Conference Papers, 2024.
MVM - IOD
Abstract
We introduce the Machine Vision Metrology Industrial Object Dataset (MVM-IOD), for evaluating 3D reconstruction, camera pose estimation and novel view synthesis of complex industrial objects. The hardware setup to acquire MVM-IOD consists of a camera, mounted upside down due to space restrictions, at the end effector of an industrial robot arm. Images of typical industrial objects are captured systematically, by moving the camera on a hemisphere around the objects. MVM-IOD contains the ground truth camera poses, the acquired RGB images, and the ground truth 3D point cloud of 9 objects and 2 background choices (alu and green) resulting in 18 scenes, which allows evaluation of all image based methods that compute a 3D reconstruction, camera poses, and/or novel views.
Dataset Samples
Alu
Green
Object 1
Alu
Green
Object 2
Alu
Green
Object 3
Alu
Green
Object 4
Alu
Green
Object 5
Alu
Green
Object 6
Alu
Green
Object 7
Alu
Green
Object 8
Alu
Green
Object 9
Dataset Creation
MVM-IOD was acquired using an Universal Robots UR3e industrial robot arm with an IDS U3-31J0CP-C-HQ Rev.2.2 RGB camera mounted at its end effector. For each object, we capture 300 images from the same camera poses. To this end, we perform a camera calibration as well a a hand-eye calibration beforehand. We obtain the ground truth of the camera poses by composing the hand-eye pose with the robot poses known via forward kinematics. The ground truth 3D point cloud of each object is obtained using a AS1 and AA85 line scan system from Hexagon with a system accuracy of 0.047 mm.

end effector of an UR3e robot arm. Here,
object 6 is captured with background alu.
sample equidistant
camera poses
on a hemisphere
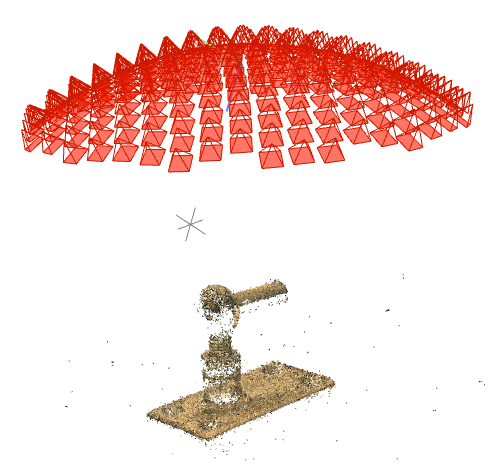
along with a SfM 3D reconstruction of object 6.
Experiments
We extensively evaluate current state-of-the-art 3D reconstruction and camera pose estimation methods, such as Structure from Motion [1], Multi-View Stereo [2], Visual Geometry Grounded Transformer (VGGT) [3], π³[4], as well as 2D Gaussian Splatting [5] on MVM-IOD and report our findings to create a baseline for future research. We found that our upside down capture setup generates images that are out-of distribution for both VGGT and π³, leading to suboptimal point clouds and camera poses. We show that in our case, out-of distribution images can be shifted closer to the training distribution by applying preprocessing steps such as rotating the images by 180 degrees and changing the aspect ratio of the images. This shows that in certain industrial applications, VGGT and π³ should be used with caution.
In the example below, we show a qualitative comparison of VGGT and π³ on the original MVM-IOD images and the preprocessed version of MVM-IOD. For VGGT, we show VGGT depth, which refers to the point cloud obtained from the depth map branch, as well as VGGT point which indicates the point cloud obtained from the point map branch.
Original Images

cropping aspect ratio
to 4:3 and rotating
by 180°
Preprocessed Images
